The AI Data Centre Infrastructure Powering Deep Neural Network Advancements
- Osinto HQ

- May 31, 2024
- 13 min read
Updated: Jan 9

Things invariably have their time and for Artificial Intelligence (AI) that empahtically seems to be right now. But why is that?
Why has this field of computer science that's been around since the 1950s suddenly made great strides forward?
It's largely down to scale. Plain old 'making stuff bigger'.
To paraphrase OpenAI's recently departed Chief Scientist and co-founder - Ilya Sutskever:
"...you just make it bigger and it'll work better..." [Source]
Big models, on big computers
What's being made bigger? In basic terms artificial intelligence / machine learning (ML) involves:
Calculating things >> Computation
Using sets of instructions >> Algorithms
Scaling up computers means building supercomputers - more specifically GPU-accelerated compute clusters.
Scaling up algorithms has largely meant creating neural networks - more specifically Deep Neural Nets (DNNs).
Deep neural network models making use of powerful supercomputer-esque GPU clusters have largely been the enablers of recent AI performance breakthroughs.
When will it end?
Not soon, probably.
For now it seems the limits of this 'make things bigger' approach to AI won't be reached for a while. This month Microsoft CTO Kevin Scott suggested that such scaling would continue to accelerate exponentially for some time yet:

In a recent interview with Reid Hoffman Scott provided some context for his assertion:
If you looked at all of the great milestone achievements in artificial intelligence...over the past 15 years...there was one commonality with every breakthrough thing - and it was that it used maybe an order of magnitude more compute than the previous breakthrough [Source]
How fast are compute requirements increasing?
In 2018 AI compute requirements were doubling around every three and a half months, according to OpenAI:
...the amount of compute used in the largest AI training runs has been increasing exponentially with a 3.4-month doubling time [Source]
Compare this to Gordon Moore's Law which successfully predicted for decades that the number of transistors the semiconductor industry could fit on a chip would double - every two years.
BIG models, deep learning - some context
AI has gone through different eras - from the logical to the statistical and now the neural. In the early 2000s Artificial Neural Networks (ANNs) started to yield much better results than other machine learning model architectures, at certain tasks.
These neural networks loosely imitate the structure of biological brains (though are far less complex) with inter-connected neurons sending and receiving signals.
Here's a very simple neural network:
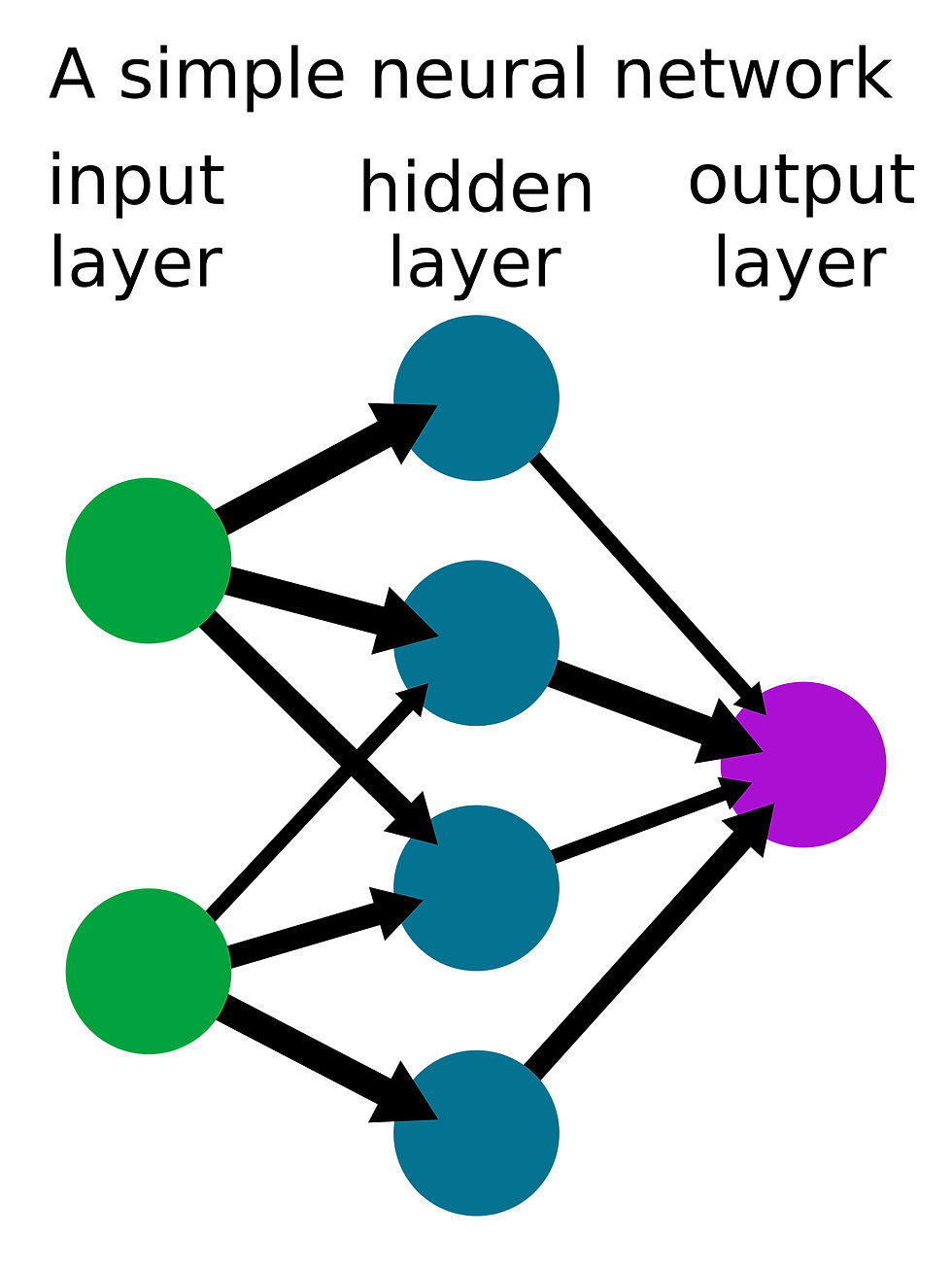
The 'neurons' pass values to one another (eg. a decimal number between 0 and 1) via the connections. If you add more layers of neurons the neural net is considered 'deep' - or a Deep Neural Network (DNN).
If you push some data through this DNN and give it example inputs and outputs to emulate, it will start tweaking the values passed along those connections - weighting them like a giant, multi-dimensional graphic equaliser.
This is the process of 'learning' or training the neural network (through back propagation). Referred to as 'deep learning' there's an excellent book about it by Professor François Fleuret of the University of Geneva called The Little Book of Deep Learning that we highly recommend for anyone interested in a comprehensive introduction to the topic - it's freely available as a pdf:

A neural network where the connections between neurons are weighted with values constitutes a 'model' - so when you hear people talking about 'AI models' there's a good chance this is what they mean - a neural network + the associated weights.
A machine learning model might consist of just two files [Source: Andrej Karpathy's excellent '[1hr Talk] Intro to Large Language Models]:
The machine learning algorithm itself, which could theoretically be as little as c. 50 lines of code and kilobytes (kb) in size
A much bigger file containing all the stored values / weights of the neural net - each one perhaps taking up two bytes of memory but the file itself being MBs or even GBs in size, depending on the scale of the network
The 'deeper' the network is the more information there is to store - because there are more layers of neurons and connections. A reasonable rule of thumb is that:
For every one billion model parameters you will need 2GB of memory
The parameters are all the different stored values and settings for the neural net. Therefore a 7B parameter model might be c. 14GB in size, a 70B parameter model 140GB and so on, most of that size being the model weights file.
AlexNet - GPUs + DNNs (+ data)
The key to teaching or 'training' machine learning models has always been to have well labelled example sets of data. There are a handful of seminal datasets in the AI / ML world that include:
A key breakthrough in AI/ML was made in 2012 when neural networks paired with Graphics Processing Units or 'GPUs' marked a significant leap forward in performance in a field used to incremental gains. The neural network was AlexNet and the designer was Ilya Sutskever - who would go on to become co-founder of OpenAI and the company's Chief Scientist until he resigned in May 2024.

The supporting research paper ImageNet Classification with Deep Convolutional Neural Networks offers a tantalising glimpse at what would come next:
...we did not use any unsupervised pre-training even though we expect that it will help, especially if we obtain enough computational power to significantly increase the size of the network...[Source]
Sutskever's realisation was that if you made the neural nets bigger and trained them for longer and on more data, they would perform better:
'"...our results have improved as we have made our network larger and trained it longer..." [Source]
Deeper networks, more neurons
AI luminary Geoffrey Hinton - Sutskever's PhD supervisor for the AlexNet project - was sceptical of his pupil's theory that you could radically increase the performance of neural networks by just adding neurons, layers and enough computational power to run them. In a recent interview he conceded that:
"Ilya was always preaching that you just make it bigger and it'll work better...It turns out Ilya was basically right...it was really the scale of the data and the scale of the computation...
We were trying to do things by coming up with clever ideas...that would've just solved themselves if we'd had bigger scale of the data and computation." [Source]
As neural nets (NNs) became 'deeper' (adding more hidden layers) and learning techniques enabled algorithms to train on less structured (messier) data (eg. through feature learning), performance began to eclipse other approaches. The neural era of AI had begun.
How big is BIG?
For an idea of the scale we're talking about - AlexNet had "60 million parameters" in 2012 - whereas OpenAI's GPT-3 in 2020 had a self-reported 175-billion parameters - around three thousand times as many.
If both of those models used two bytes to store each parameter, how big would they be?
AlexNet: 60 million parameters @ 2 bytes each = 120MB
GPT-3: 175 billion @ 2 bytes each = 350GB
Think of that in terms of consumer hardware. To 'run' the models you need to load them from storage into memory (RAM). So AlexNet should in theory be able to run on a 2010 iPhone 4 with 512MB of RAM quite comfortably*.
Conversely the GPT-3 model at 350GB couldn't even run on today's (May 2024) highest-end, top spec M3 Max MacBook Pros** - which come with an absolute maximum of 128GB of RAM. The point here is that big models need computers with a lot of memory.
Keep in mind that this is only the model size, if you want to push a big batch of data through it for training - like The Pile (825GB) or FineWeb (74.2TB) - then you also need to fit those somewhere in your machine(s).
We're going to need bigger computers...
*If RAM were the only requirement, which it's not **It actually probably could if it were quantised as models often are for inference
BIG computers
Once your computing requirements exceed what you can cram into a 'tower' you get into the nerdy world of server racks and quite quickly after that - data centres. They're usually rather dull looking industrial buildings crammed full of computers, wires, air conditioning and cable ties.

Until recently a typical data centre 'rack' might hold a mix of hard drives, ethernet switches and servers in it. They can have a wide variety of hardware in because you just rent the space, pay for the electricity and then fill them out with whatever you want.
Data centre hardware is quite fussy - it wants nice stable temperature and humidity levels in which to operate. The payoff is that they're pretty robust bits of kit, by and large - with around 5 years of 24/7 service being a fair expectation.
They are however expensive, and data centre rental fees aren't cheap either. Discounts of course are best for the biggest customers renting the most space on the longest-term deals. A data centre business is in essence a real estate business, or if you want to attract investors with the deepest pockets it's 'a digital infrastructure play'.
Rent and bills
The cost of the electricity in data centres has never been an especially significant part of the cost - until you get to very large scale operations, hence big tech companies building their own data centres near sources of cheap power or even building power generation for their data centres themselves.
You'll typically pay around the wholesale electricity price + some extra to pay for the cooling (a 'PUE' factor) + a some profit margin for the operator. This cost varies across countries - from as little as $0.05/kWh in hydropower-rich Norway to $0.40/kWh or more in places like the UK where wholesale gas prices drive the cost of electrical power.
A rack filled with computers for general purposes will typically have some CPUs, RAM, storage and switches. They're cooled by little electric fans and the data centres HVAC. Data centres to date have typically divided up their total electricity between all the racks, allowing for a maximum of c. 5kW of electricity per rack - equivalent to a few electric kettles boiling.
The era of accelerated computing
Until AlexNet in 2012 most processing was done by CPUs. They're the jack of all trades of the computing world, good at lots of things but not excellent at any one kind of computation. It turned out that GPUs were much faster than CPUs at certain types of mathematical calculation. In particular they excelled at things like matrix multiplication - just the type of computation you do a lot of when working with certain types of machine learning algorithm.
Instead of waiting for a CPU to trudge through sums it wasn't great at AlexNet proved that if you could throw this type of calculation at a specialised bit of hardware - a GPU - it could do it much faster. Even better, why not use a whole bunch of GPUs and have them working on different calculations concurrently - parallelism - which is historically what supercomputers have done, hence our use of that term in reference to GPU clusters.
NVIDIA, GPUs and power

Released in 2017 the Tesla V100 GPU had up to 32GB of fast (for the time) HBM2 memory [Source]. How can you work with models that are hundreds of GBs, which you're trying to push TBs of data through, with a GPU that has only 32GB of memory?
You put multiple GPUs on the same server and a blazing fast inter-connect between them - like NVIDIA's is NVLink (AMD's equivalent is Infinity Fabric). These are GPU-accelerated servers and will typically have up to eight GPUs, a couple of CPUs, quite a lot of RAM and maybe some fast solid-state NVMe storage.
GPU accelerated servers
You'll typically find up to eight GPUs connected like this in a single server - also referred to as a 'node'. With the V100 GPUs we just mentioned thatgives us 8 x 32GB = 256GB of memory to work with. The eight GPUs, with the right software (like NVIDIA's industry-leading and proprietary CUDA or AMD's less favoured but open source ROCm) can effectively be used like one big, powerful computer that makes use of all of the pooled memory resources. Clever stuff.

You can see from my crude labelling on the image above that the GPUs take up quite a bit of space, a lot of that due to the enormous heat sinks on them. This sort of 'GPU-accelerated' server also uses a lot more power than a conventional or 'general purpose' compute server:
Pulls about 3.8 kW at peak, but we spec out the full 4.4kW (2x2.2kW + redundant) in the datacenter [Source]
A thirst for power
The majority of the global data centre industry is built upon an average of c. 5kW of electrical power made available to each rack of computers. Just one GPU-accelerated server can use all of that power, or more.
Ask NVIDIA what the single biggest barrier to enterprise adoption of AI is, and they'll tell you it's that there's simply not enough data centre space designed and built to accommodate GPU-accelerated server levels of power consumption.
The problem becomes clear when you add scale. Because you don't stop at 8 x GPUs in one node. If you connect these servers together with extremely fast networking like Mellanox's Infiniband (NVIDIA acquired them in 2019), you can pool a lot more than eight GPUs together.
By 2020 Microsoft had built a cluster of 10,000 V100 GPUs connected by Infiniband for OpenAI to use for GPT-3 [Source] - that's a theoretical maximum of 320TB of pooled GPU memory to work with.
In reality the models and data are split up or 'sharded' in a range of different ways. Knowledge of how to distribute neural net training workloads across large GPU clusters is incredibly valuable, quite rare and rumoured to be more art than science.
Even at the best labs with the best engineers and data scientists it's rumoured that as many as half of all attempted Large Language Model (LLM) training runs end in some sort of failure [Source].
Rise of the multi-thousand GPU cluster
It's worth reflecting that the widespread use of such large, GPU-accelerated compute clusters is a quite new phenomenon. OpenAI founding team member (and until recently Director of AI at Tesla) Andrej Karpathy himself conceded this week that:
In ~2011...If you offered me a 10X bigger computer, I'm not sure what I would have even used it for...Today, if you gave me a 10X bigger computer I would know exactly what to do with it, and then I'd ask for more. [Source]

Reference architectures freely available online from NVIDIA give quite detailed instructions on how to build 127 node GPU clusters - at 8 x GPUs per node these so-called 'scalable units' are 1,016 GPU clusters:

The H100 GPUs which are the industry 'favourite' at present (and not available in China due to to US sanctions) have 80GB of memory per GPU, so a 1k GPU cluster has a theoretical max. of c. 80TB of pooled memory to work with - enough to fit a 40 trillion parameter model.
There are orders and deployments being made today for 1k, 2k, 4k, 8k and even 16k GPU clusters. Meta alone claim to be targeting a fleet of 600,000 GPUs by the end of 2024 and Microsoft Azure's largest H100 cluster already has 14,400 GPUs - it is ranked as the third most powerful supercomputer in the world [Source]:

Whilst a 40 trillion parameter model might sound ludicrously large, some have guessed that GPT-4 was already at 1.76 trillion parameters. There doesn't seem to be an end to scaling in sight just yet.
Power and money
A single NVIDIA H100 GPU sells for around $30-40,000 at the moment. An 8 x H100 node server for $300-400,000. Therefore if you're the world's worst negotiator and get no discount on ordering your 127 node cluster you should expect to be shelling out 127 x $300,000 = $38.1m USD.
You'll then want to add a finger in the air 30% on top for Infiniband networking, bringing us just shy of $50m USD CAPEX for a cluster that probably can't even train state-of-the-art deep neural nets because they're already too big.
Then there's your power bill to consider. Every H100 GPU can use up to 700 watts of power, servers with eight of them in can pull over 7kW each. If we follow NVIDIA's reference architecture each rack of four nodes gets close to needing 50kW of power - that's about enough to give a Tesla 3 sized electric car a full charge - that'll get you 200-300 miles. That's one H100 node in one hour (very approximately).
Megawatt-scale compute clusters

A 128 node cluster of H100s would have a theoretical power draw of around 1.6MW at full load - that's very roughly the same amount of power an average onshore wind turbine might produce at full capacity.
You'll also notice that the average power density per rack here is around ten times what most data centres were designed for - 50kW vs 5kW. That's the reason Facebook and others temporarily froze all Capex expenditure on data centres in recent years - they had to cleansheet their entire data centre designs to accommodate GPU accelerated servers and their huge thirst for power.
Not cool
The next headache is cooling - air conditioning and fans in the servers can just about cope with a maximum of 50kW per rack, much above that and some sort of liquid medium is required to better dissipate the heat (usually water or a water-glycol mix).
We'll do a separate post on data centre cooling for AI - it's a fascinating topic that includes everything from rear door cooling and liquid-to-chip to computers fully immersed in tanks of mineral oil.
Let's end with some quick math on the electricity cost of operating a 1.6MW H100 GPU cluster. If we add a very lean 1.1 multiple (to allow for the power our cooling system uses) we're looking at a theoretical maximum 1600kW / hr x $0.40 x 24 hrs = $15k per day in electricity at UK wholesale prices - or a cool $5.5m / year. We've not even factored in hardware depreciation yet, perhaps the biggest cost of all, but that's for another day.
In conclusion
Deep Neural Networks (DNNs) are going to keep getting bigger, and better.
The computational requirements for DNNs (massively parallel GPU clusters) are therefore likely also going to continue to grow.
The limiting factors to scaling deep learning on GPU clusters are likely to be:
Financial return / runway - only those who can cover the CAPEX and/or OPEX of GPU cluster build/operation/rental - whilst building out revenue generating products - will survive
Available power - a 10x increase in power demand will see most data centres max out their power long before their rack space - electricity distribution networks take time to build, and there's other competition to secure available power



Comments